分享内容:
1.王卫军:《Weisfeiler-Lehman Neural Machine for Link Prediction》 KDD’17
Weisfeiler-Lehman Neural Machine for Link Prediction
Muhan Zhang and Yixin Chen, KDD 2017
主要内容
论文中作者提出基于Weisfeiler-Lehman Neural Machine(WLNM)进行链接预测的新方法。WLNM通过提取每个节点的邻近子图,并将子图编码为邻接矩阵,利用NN进行节点间的链接预测。WLNM具有无可比拟的优势,包括比最先进的方法具有更高的性能,以及在各种网络上的普遍适用性。
论文中,基于快速散列的Weisfeiler-Lehman(WL)算法对图进行编码,该算法根据子图中的结构角色标记顶点,同时保留子图的内在方向性。之后,在这些邻接矩阵上训练神经网络以学习预测模型。与传统的链路预测方法相比,WLNM不假设特定的链路形成机制(例如公共邻居),而是从图本身学习这种机制。通过实验,表明WLNM不仅优于大量最先进的链路预测方法,而且在具有不同特性的网络中始终表现良好。
内容材料来源于作者主页
https://www.cse.wustl.edu/~muhan/
详细内容
应用领域:
链路预测:
给定一个不完整的网络,预测网络中的两个节点之间存在链接的可能性。
社交网络中的朋友推荐
电子商务中的产品推荐
其他: 代谢网络中的反应预测、知识图谱补全……
2 目前常用的链路预测方法——启发式方法

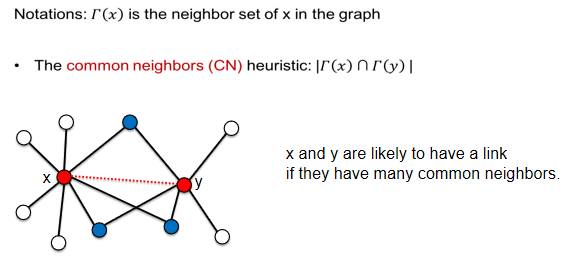
2.1共同邻居预测方法
2.2 PA方法

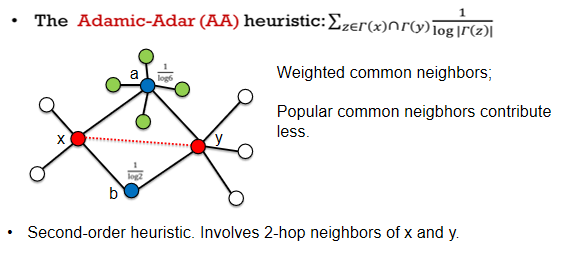
2.3 AA方法
2.4 Katz方法

2.5 启发式方法的问题
2.5.1 问题
自Libon-Nowell和Jon Kleinberg首次引入链接预测问题以来,LP有超过50种不同的启发式方法,每年都会出现关于设计新链接预测启发式的相关论文。
问题
(1)链路预测没有通用的启发式。启发式可能在某些特定类型的网络上运行良好,但在其他网络上可能表现不佳。
(2)现有的启发式还不能在某些网络上很好的运行。

2.5.2 原因
主要原因在于启发式规则:
(1)假设一种特定的链接形成机制
(2)手动提取得图特征
基于以上内容,作者提出利用Weisfeiler-Lehman Neural Machine (WLNM)直接学习网络的特征(WLNM是一种用于链接预测的神经网络模型,它自动从链接的邻近子图中学习图特征)。
3 Weisfeiler-Lehman Neural Machine
3.1整体框架
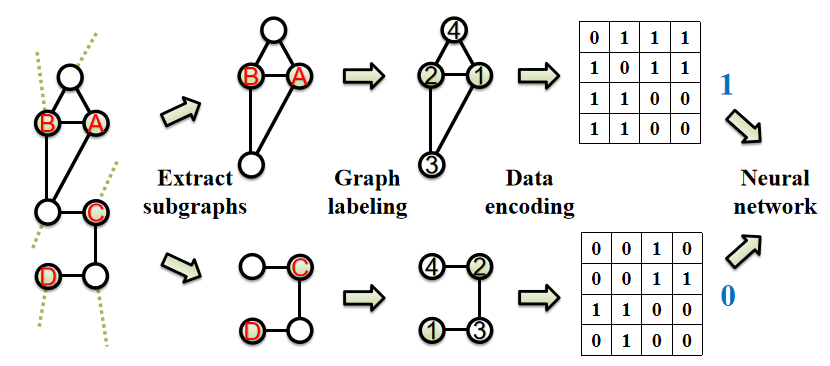
3.2邻近子图抽取
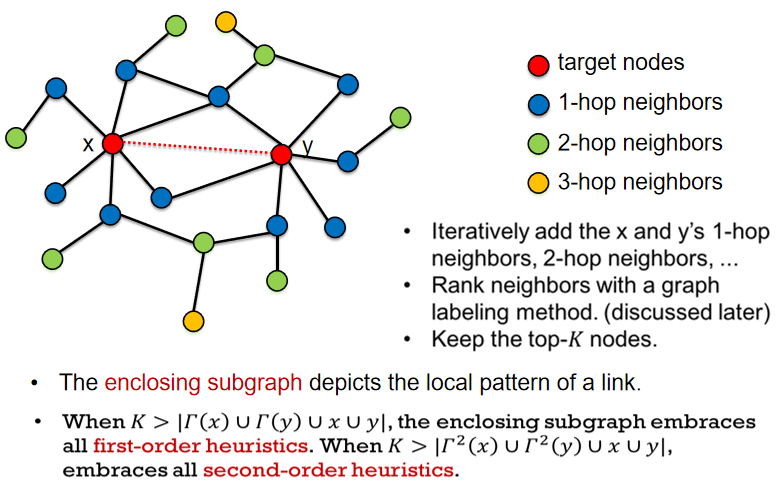
给定目标节点x和y,迭代添加它们的1-hop邻居,2-hop邻居,3-hop邻居等等,直到子图具有多于K个节点。 然后使用图标记方法对这些相邻节点进行排名。 最后,保留top-K节点并为目标链接构造一个邻近子图。
邻近子图实际上描述了链接的一种本地模式,该链接可能包含有关此链接是否可能存在的大量信息。 此外,随着增加K,邻近子图将逐渐包含计算1-hop,2-hop和h-hop启发式所需的所有信息。 例如,在该子图中,它包含x和y的所有1-hop邻居和2-hop邻居,因此可以基于该子图计算所有1-hop和2-hop启发式。
3.3 图标记
3.3.1 定义顶点的顺序
图标号是一种将正整数标号或颜色分配给图顶点的算法,如下图。
图标号方法有两个要求:
首先,它应该根据顶点在子图中的结构来标注顶点,也就是说,两个不同子图的两个节点应该有相似的标签当且仅当它们在各自的图中具有相似的结构角色。这对于机器学习模型以一致的顺序读取不同的子图非常重要。
第二个要求是,图标签还应保持子图的内在方向性。这是因为一个封闭的子图是通过迭代地从中心向外添加新的节点来构造的。例如,我们可以通过让靠近中心的节点比更远的节点具有更小的标签来实现这一点。这样,我们就可以将方向性信息编码到图形标签中。

3.3.2 WL算法
结构信息
它首先将初始1分配给所有图形顶点。 然后它通过连接自己的标号和它的邻居标号来为每个顶点构造一个签名字符串。 之后,所有签名字符串都按词汇顺序压缩为新的正整数。 重复该过程直到收敛。
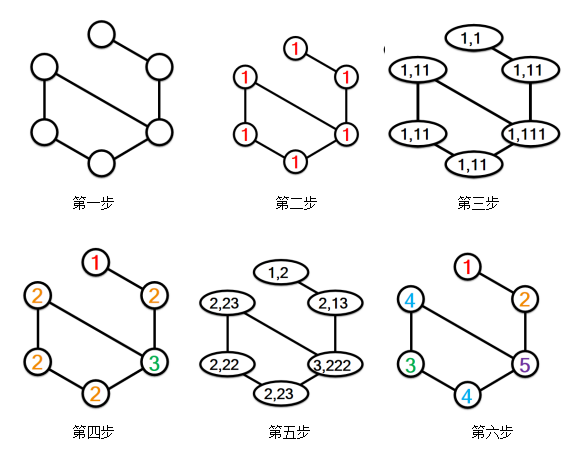
方向信息
如何让WL算法用颜色编码方向性信息呢? 可以通过根据节点到中心的距离为节点分配初始颜色,而不是将初始颜色分配给所有节点,从而轻松实现这一目标。 例如,将初始颜色1分配给两个目标节点x和y,并将初始颜色2分配给所有1-hop邻居,将3分配给所有2-hop邻居,依此类推。
之后,在这些初始颜色上运行经典WL算法以获得最终颜色。 经典WL算法的颜色顺序保持属性,确保最终颜色仍然遵循基于距离的初始颜色顺序,正如在这个例子中看到的,在颜色收敛之后,所有的1-hop邻居,蓝色圆圈,仍然具有颜色比2-hop邻居小。 所有的2-hop邻居,绿色的,仍然比黄色的颜色更小。 这种颜色顺序保留属性使我们能够将方向性信息编码到这些图形标签中。如下图(1-3步):
第一步

第二步
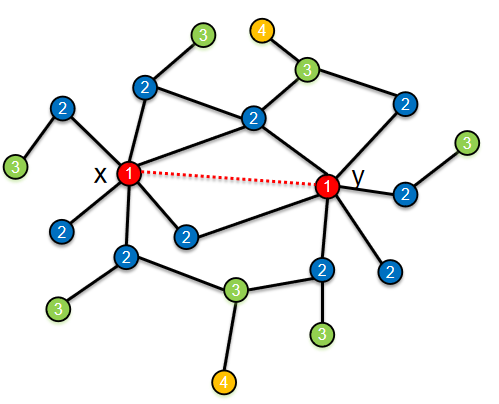
第三步
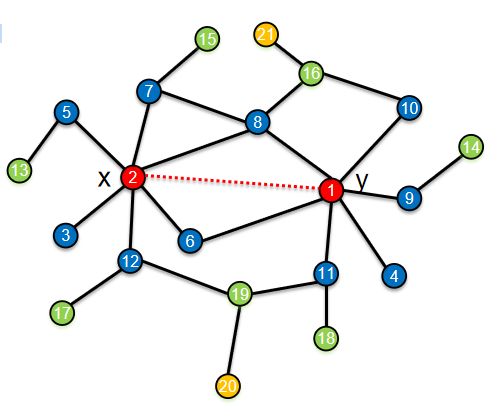
经典WL的颜色顺序保持特性确保最终颜色也观察到初始颜色顺序。但经典WL算法很慢,因为它需要迭代地读取,存储和排序可能非常长的签名字符串,从而引入了许多不必要的IO负担。 最近,有一个基于hash的WL算法,它使用hash函数将唯一的签名映射到唯一的实际值,使WL能够直接操作实际值而不是字符串。 它比传统的WL快得多,但不再保留颜色顺序。 此外,由Hash-WL产生的颜色有时不会收敛。 为了解决这些问题以及保持基于散列的WL的效率,我们提出了Palette-WL算法。
palette-WL算法使用类似于hashing-WL的散列函数,除了添加一个规范化项之外。作者证明,palette-WL仍然是一个完美的散列,并进一步为颜色顺序保持。利用这个归一化散列函数,也可以严格地证明颜色的收敛性。作者称其为palette-WL,因为标记过程就像从palette到vertices绘制初始颜色,然后迭代地通过混合它们的原始颜色和附近的颜色,从而保持颜色的相对顺序。
3.4 数据编码
在确定节点标签之后,作者将每个邻近子图编码成邻接矩阵并将其送到神经网络中。

Given the converged WL colors, we can determine the vertex order based on these colors and construct an adjacency matrix. We can see that, because of the color-order preserving property of palette-WL, the two target nodes will always have the smallest final colors in the end. So this guarantees that the target link is always encoded in A12 of the adjacency matrix shown as the yellow star here. This is important, since otherwise this yellow star may appear arbitrarily in the adjacency matrix, so that neural networks cannot distinguish which is target link to predict.
After the encoding, this upper-triangular adjacency matrix is vertically fed into a three layer fully connected neural network to train a link prediction model.
给定收敛的WL颜色,我们可以基于这些颜色确定顶点顺序并构造邻接矩阵。可以看到,由于palette-WL的颜色顺序保留了属性,两个目标节点最终总是具有最小的最终颜色。 因此,这保证了目标链接总是在邻接矩阵的A12位置中编码,在此处显示为黄色星形。 这很重要,因为如果这个黄色星可能在邻接矩阵中任意出现,神经网络将无法区分哪个是目标链接来预测。
在编码之后,将该上三角形邻接矩阵垂直馈送到三层完全连接的神经网络中以训练链路预测模型。
4 可视化实验及与其它算法的对比
论文对几种常见的网络进行可视化实验,并与其它算法进行对比。得出如下结论:
(1)WLNM不使用启发式方法,而是自动从链接的邻近子图中学习用于链接预测的图特征。
(2)基于颜色顺序保留 hashing-based WL算法,称为Palette-WL,用于强加顶点排序。
(3)在大多数benchmark数据集上胜过所有启发式方法。
(4)在很少有现有启发式算法可以很好地运行的网络上表现很好。
(5)是一种下一代的链路预测方法,具有最先进的性能,具有跨不同网络的通用性。