
PackOne致力于实现主流大数据软件在云端的快速弹性部署。通过对云API和Apache Ambari API的联合调用,完成Hadoop、Spark、NiFi、PiFlow、Kylin、MangoDB、Neo4J等流行的大数据管理/处理软件在云端的一键部署和一键伸缩。主要特性包括:
1、支持在空白虚拟机上完成大数据处理集群的全自动部署。
2、通过Apache Ambari对已部署的大数据软件进行状态监控、配置管理。
3、通过将模版集群物化为系统镜像,实现新集群的分钟级快速部署。
4、通过集群节点的全自动增删,实现各类大数据软件处理能力的分钟级弹性伸缩。
5、在同一个界面上对来自不同云的虚拟机、存储卷、镜像、模版等进行CURD操作。
PackOne支持不同类型的云平台。目前版本实现了对OpenStack和EVCloud两款私有云的适配。
packone 界面示例1
packone 界面示例2
##一、安装
选择一台能够访问目标云的Linux主机 (以Centos 7.5为佳),依次执行:
pip install pk1
pip install -U pip setuptools
##二、配置
创建一个Postgresql数据库实例,并准备好其连接信息,包括:db_user(数据库用户)、db_passwd(用户密码)、db_host(数据库主机地址)、db_port(数据库端口号)、db_name(数据库名)。然后执行:
pk1 setup --database db_user:db_passwd:db_host:db_port:db_name
(会提示设置管理员admin的邮箱、密码等信息。)
##三、运行PackOne服务
pk1 start [--listening 0:11001]
##四、快速上手:以OpenStack私有云为例
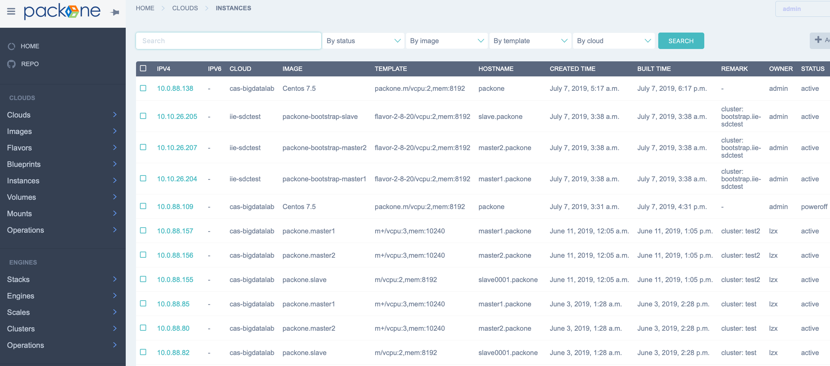
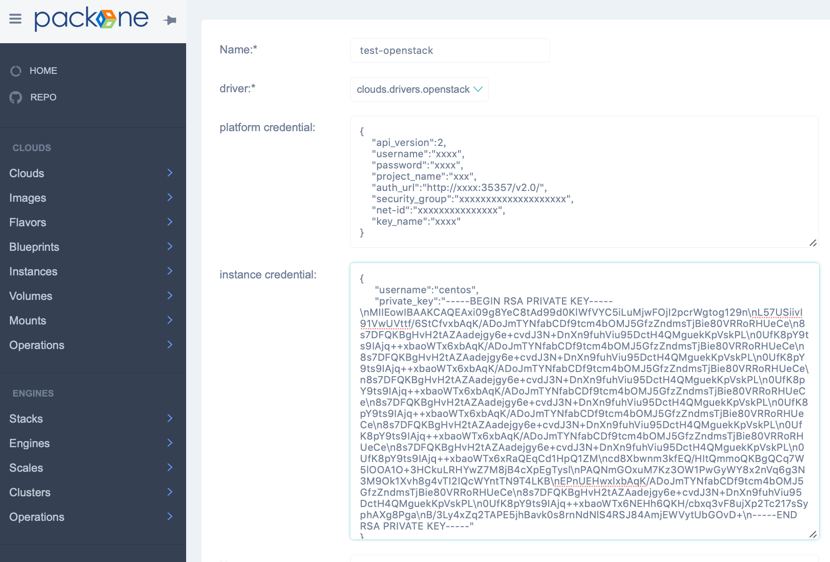
访问网址:http://packone-server-ip:11001 进入添加“云”的界面,输入如下图格式所示的OpenStack用户密钥信息。创建成功会自动导入云端的镜像、模版。然后进入user/profiles界面,为当前用户添加一个profile,进入user/balances界面,为该profile在新添加的云上添加余额(大于零即可)。
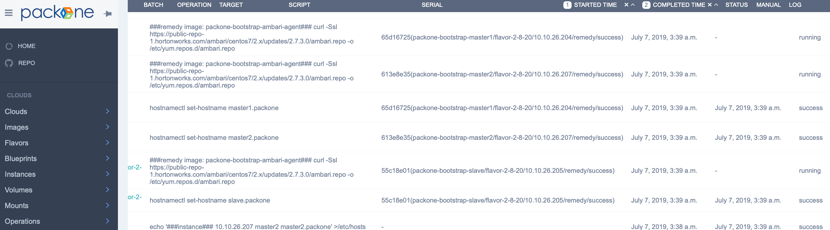
回到云列表界面,选择刚才新创建的云,在操作下拉框点选“bootstrap…”按钮,触发在空白虚拟机上全自动部署模版集群的后台工作流。通过clouds/operations界面可监控工作流的执行进度,若遇到某步操作出错,可以点按re-run按钮重新执行,直至成功。
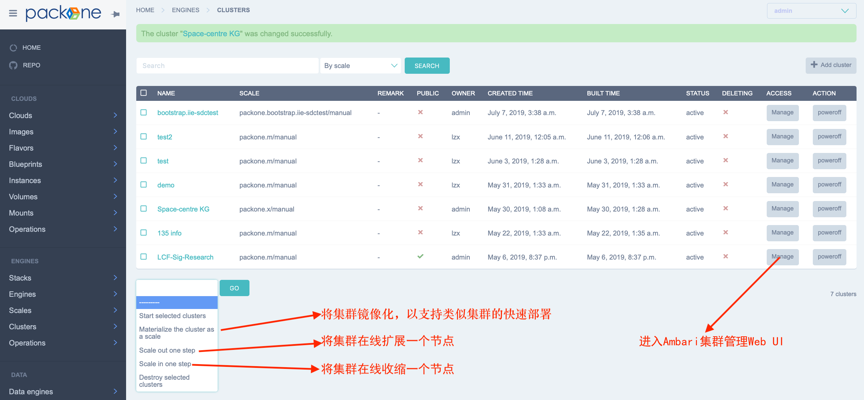
当工作流执行完毕后,可以在engines/clusters界面选择刚才创建的名为bootstrap.<云名称>的模版集群,点按“Materialize the cluster as a scale”将其镜像化。最后,创建新集群时,可在engines/cluster的创建集群界面选择名为“packone.<云名称>”的scale,实现新集群的快速创建。
##五、停止PackOne服务
pk1 stop
PackOne目前以Apache License v2.0 协议在GitHub(https://github.com/cas-packone/packone)、Gitee(https://gitee.com/opensci/packone)上开源。欢迎提交Issue、PR。
##六、相关链接
PackOne 的详细介绍:点击查看 (https://www.oschina.net/p/packone)
PackOne 的下载地址:点击下载 (https://www.oschina.net/home/login?goto_page=https://www.oschina.net/news/108047/packone-0-1-b3)